Using New York Taxi Data To Estimate Traffic
This blog is based on an ongoing research project.
Keywords: Graph Convolution, PostgreSQL, LSTM, Big Data, Taxi, Traffic Estimation.
Introduction
With the advancement of technology penetrating into several aspect of life, the amount of data generated is growing as fast as ever. In 2013, it is estimated that 90% of the world data was created during 2011-2012 alone. In addition, research in artificial intelligence have been gaining traction with numerous success application, such as computer vision, natural language processing, or neural network, and these framework benefits greatly from the data. These trends are accompanied by the advancement in computing power, which is being more powerful and accessible to researchers compare to several years before when such algorithm is considered infeasible. Therefore, data has been identified as a new resource that is as impactful to the economy as the traditional one (e.g., minerals, oils, etc…).In the transportation field, one such data is the New York taxi data where there are upwards of 1.1 billion taxi trips recorded from 2009 to 2015. This data is generated as part of the Open Data Law and recorded by the New York Taxi & Limousine Commission (NYC-TLC). With such enormous size, this data is perfectly capable of fueling a deep learning model. Figure 1 shows the Manhattan road network, pickup, and dropoff density.
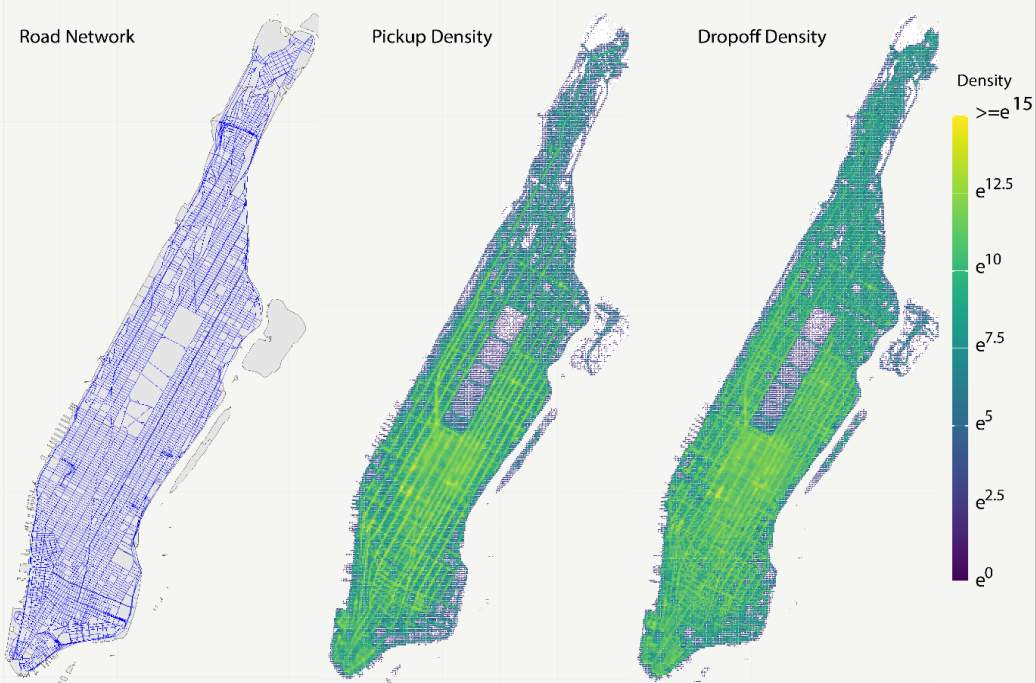
Figure 1. Manhattan Road Network, Pickup, and Dropoff Density
Taxi data provides an insight into this problem since for every taxi trip, we can know the pickup and dropoff point, the pickup time, total distance, and total travel time. Therefore the objective of this research is “to develop a sequential three step framework that use a single taxi dataset to estimate complete network link travel time, disaggregated by time of the day”. We believe this will be very beneficial to dense urban areas where travel time information is vital and taxi activities are frequent.
Figure 2. Example of DU-LTE
Methodology
Taxi data only contains the pickup and dropoff point whereas the full trajectory is not available due to privacy reason. However, thanks to the excessive amount of taxi trip records, we propose the following three steps framework shown in Figure 3 below:
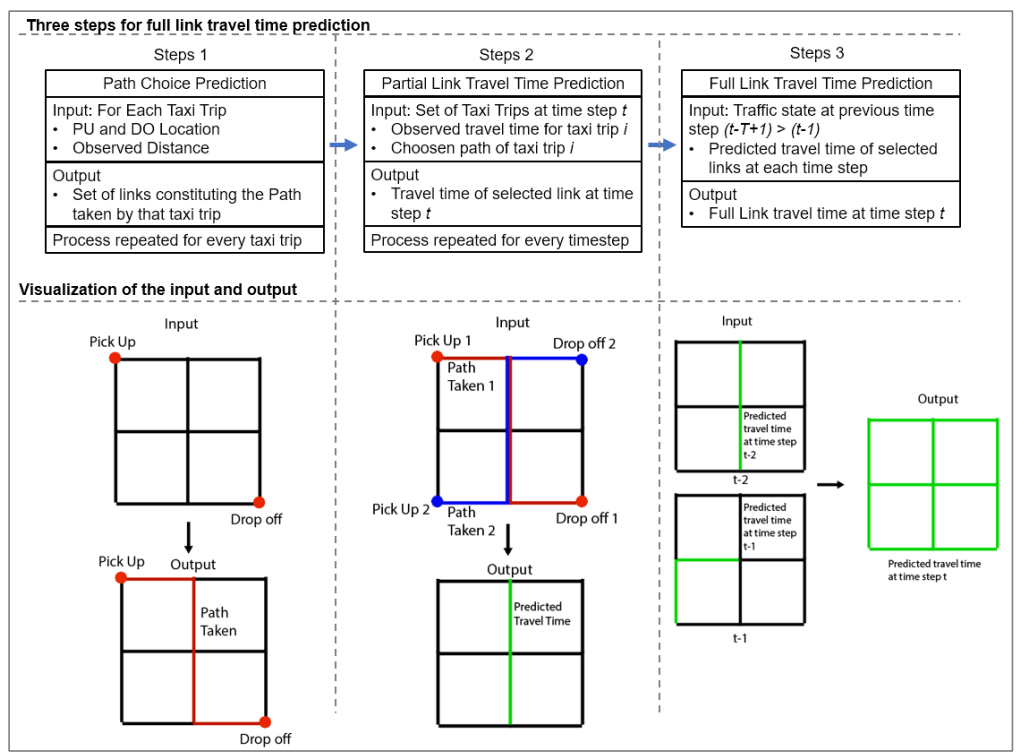
Figure 3. Three Steps Framework
In step 3, we use a model called Traffic Graph Convolution Network (TGCN). In essence, the road network can be represented as a graph where each vertice is an intersection and the edge is the road segment connecting these intersections. These nodes can then learn information from its neighbor to estimates its own travel time. For example, in Figure 4, the node u can learn travel time from its neighbors v1, v2, v3,_ and v4. By repeating the TGCN operation multiple times, node u not only can receive information from its nearest neighbors but also neighbors that are further away. The mathematical formulation behind TGCN operation is also simple and elegance which facilitates the ease of training.
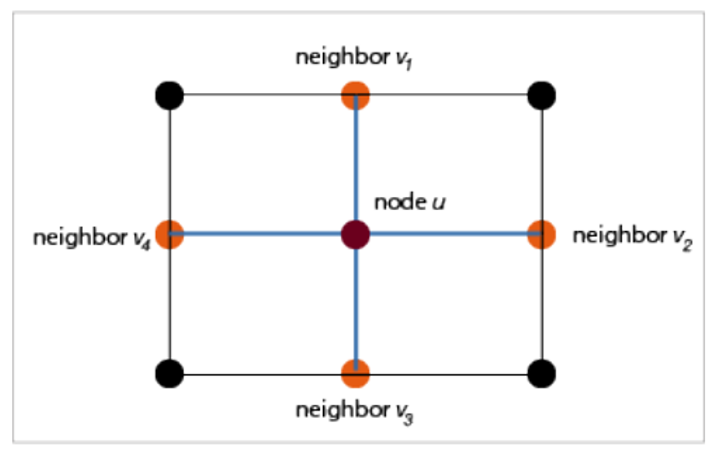
Figure 4. Representation of TGCN
Author's Contribution in this project
The author is responsible for the problem concept, methodology, modeling in software, and writing of the paper. First, the taxi dataset is downloaded and stored in a PostgreSQL and geocoded with PostGIS. Second, OpenStreetMap data is used for New York city road network and the raw taxi data is mapped into the road network’s real node. Figure 5 shows an example of data mapping. Parrallel computing is used to accelerate this pre-proccessing process. The Traffic Graph Convolution Network is coded in a python script using Tensorflow Functional API. The predicted path is generated by the Yen’s kth-shortest path (KSP) algorithm from the pgRouting package of PostGIS.
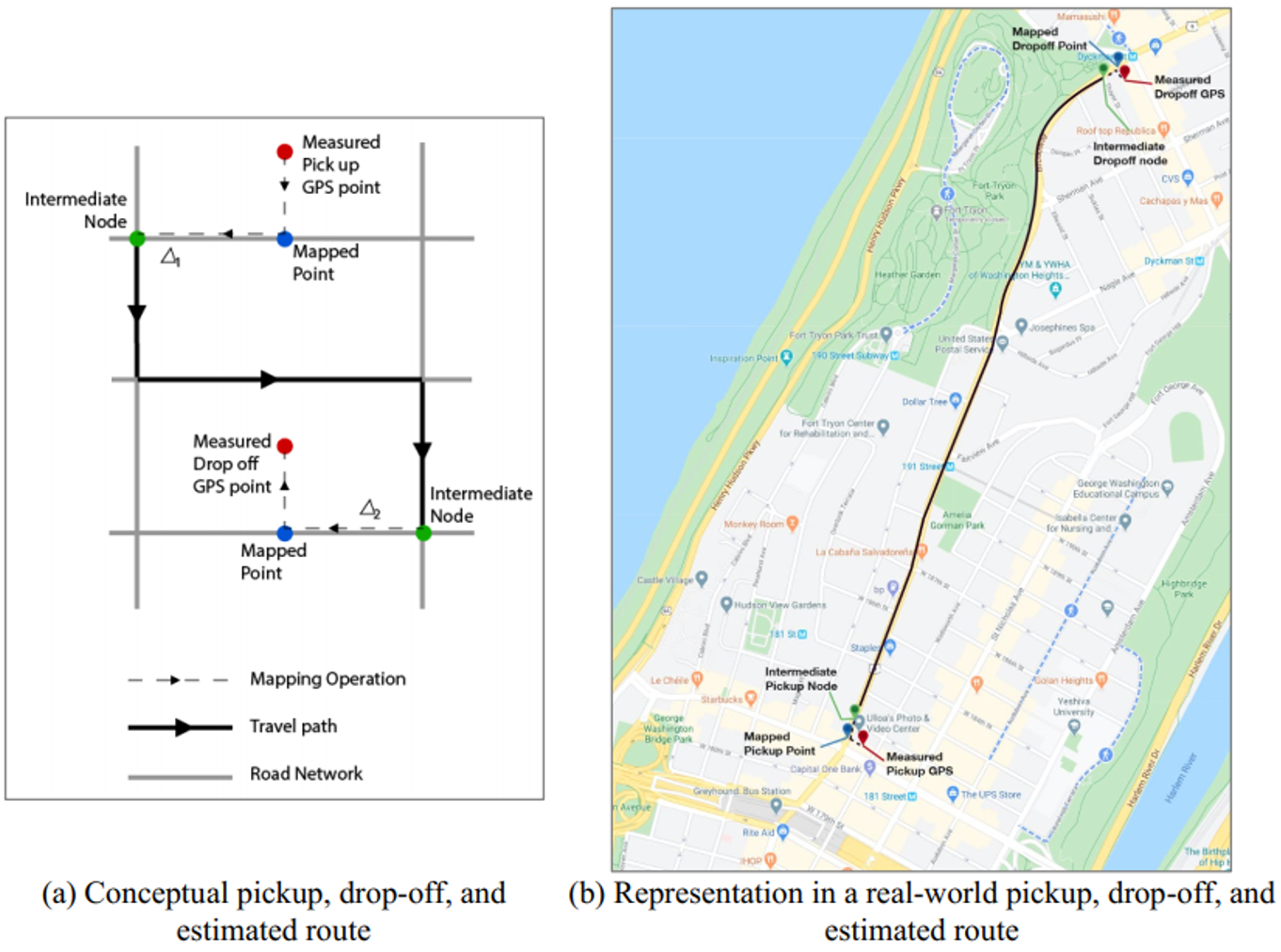
Figure 5. Example of data mapping